It started as a simple question, can we do something fun and interesting to help the charity Movember? This quickly turned into a brainstorming session that resulted in a number of ideas, where we eventually settled on Mo-lebrity: a site where someone can take a photo of themselves and see which moustache-wearing celebrity they look the most like.
The next step was then to figure out how to make this work. We set ourselves another goal, to make this all serverless. Which means that we didn’t want to use any servers or traditional databases and instead only use AWS services like Lambda, DynamoDB, and of course Rekognition. This post aims to take the hood off and give a peek at how we made this all work together.
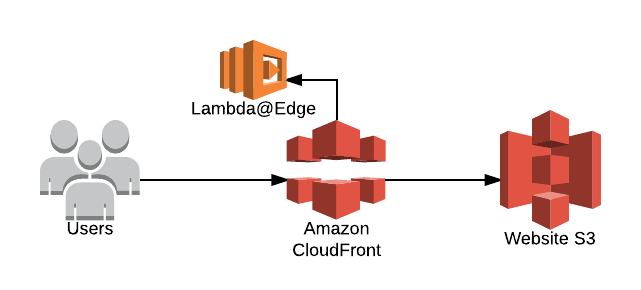
The interface you see when you visit the website is created using the JavaScript framework React. This allows it to run on S3 without the need for any servers to host the website itself. In front of this is Cloudfront, and Lambda@Edge to provide some extra functionalities.
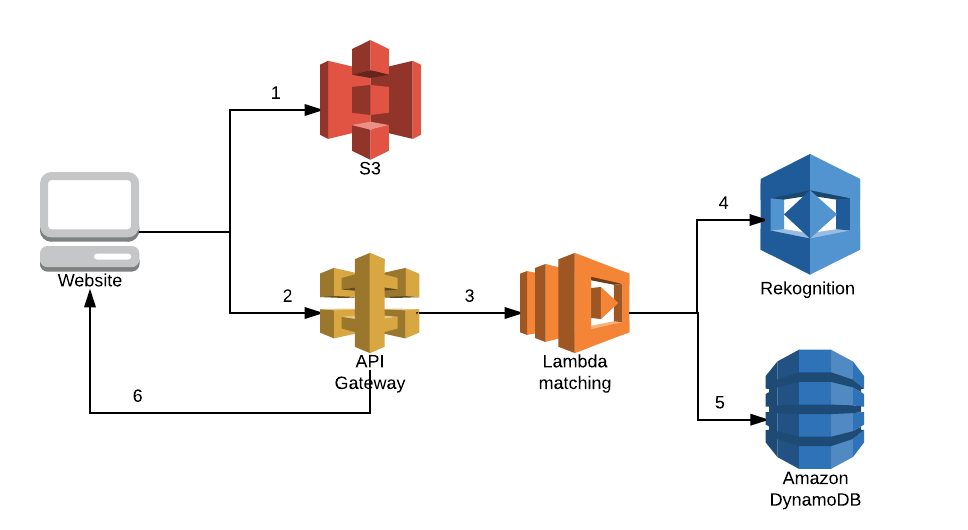
Just having a good looking website is not enough however, after all it needs to do something. Which means we needed a good matching functionality. In order to match a celebrity the website pushes the photo up to S3 (1), which has lifecycle rules set to delete the photo as soon as possible, and then goes through an API Gateway (2) to call the Lambda function for matching (3) to do the matching. The Lambda function uses Rekognition (4) to compare the photo in the S3 bucket to a set of images we collected. The function takes the closest match, and collects metadata about this photo from DynamoDB (5). Then it returns the photo and metadata to the website (6) which displays it for you to see how your Mo matches up.
This then leaves the question of how the Rekognition collection was created. For this we built code that goes through a Wikipedia page of famous people, follows each link, checks if it describes a person, and then collects the URL of the image as well as metadata such as the attribution for the image. This image is then passed through the Rekognition Celebrity API to confirm it is indeed a celebrity.
Based on this match we also retrieve the name of the celebrity, to ensure it is correct. After this match, the image is put through the face detection API which tells us the likelihood of the person having a moustache. Based on this percentage the celebrity is then added to a Rekognition collection including, if it matched high enough, the collection that is used by the matching code.
All of this is held together by the Serverless framework, which took care of a lot of the boilerplate functionalities for us so we could focus on the functionality we wanted to build.
For us, building this was a fun learning experience for a good cause. If you want to have a look at the code, stay tuned as we will be releasing this soon, in the meantime you can see who your mo-lebrity match is on the site, and of course feel free to make a donation to this good cause.