In my ongoing quest for automating all deployment related matters, I discovered I needed a way to pull in single files from S3 for my Wercker builds. As I couldn’t find a step for that, I built one.
Background
Last night’s Go meetup was partially a hack night, so I was planning to do some work on Igor. Usually I spend most of the time at hack nights talking to people, but I do occasionally get something done as well. So, after I wrote a small change for Igor I then needed to deploy this.
As it happens, I run Igor in a couple of Slack teams and I was bothered by the fact that I had to do these deployments manually. After all, that’s what I built the Lambda deployment step to solve. The issue of course is that Igor uses a configuration file, and as that file contains various keys I didn’t think that putting it up on GitHub was a great idea.
There are different solutions for something like this, but to keep things simple I decided to store these configuration files in an S3 bucket and pull them in during the build. The question then became, how do I pull these in? I couldn’t find a step that does this (or at least, not one that is actively maintained) so once again the solution was to build one myself.
The Step
As with my other AWS related step, I decided to build a simple Go application for it. And once again, it’s a really simple one. In fact, for this it can/should probably be extended for better supporting everything S3 can do1. A lot of the below is very similar to what I wrote for the Lambda deploy step, but there are obviously some differences.
func main() {
svc := s3.New(session.New(), &aws.Config{Region: aws.String(region)})
params := &s3.GetObjectInput{
Bucket: aws.String(bucket),
Key: aws.String(key),
}
resp, err := svc.GetObject(params)
if err != nil {
fmt.Println(err.Error())
os.Exit(1)
}
bytes, _ := ioutil.ReadAll(resp.Body)
if filename != "" {
ioutil.WriteFile(filename, bytes, 0644)
} else {
fmt.Print(string(bytes))
}
}
With the flag boilerplate code stripped out, the above is all there is to the main function. I just retrieve the file and if a filename is provided it is stored as such, otherwise it will print the output2.
The run.sh code is also not very interesting, with the major new thing being that if a filename isn’t provided it will use the key instead. The key in this case is the identifier/name of the file in S3.
if [[ -z $WERCKER_S3GET_FILENAME ]]; then
WERCKER_S3GET_FILENAME="$WERCKER_SOURCE_DIR/$WERCKER_S3GET_KEY"
fi
S3GET="${WERCKER_STEP_ROOT}/s3get --bucket ${WERCKER_S3GET_BUCKET} --region ${WERCKER_S3GET_REGION} --key ${WERCKER_S3GET_KEY} --filename ${WERCKER_S3GET_FILENAME}"
update_output=$($S3GET)
The compiling and deploying of this step is exactly the same as the Lambda one, so I won’t bore you with that again.
Using the step
My stated use case for the step is for Igor deployments. So let me quickly show how I use it there.
- script:
name: Prepare for personal releases
code: |
mkdir -p personal/ignoreme personal/gang zips
cp main index.js personal/ignoreme
cp main index.js personal/gang
- arjen/s3get:
access_key: $AWS_ACCESS_KEY
secret_key: $AWS_SECRET_KEY
bucket: igor-configs
key: ignoreme.yml
filename: $WERCKER_SOURCE_DIR/personal/ignoreme/config.yml
- arjen/s3get:
access_key: $AWS_ACCESS_KEY
secret_key: $AWS_SECRET_KEY
bucket: igor-configs
key: gang.yml
filename: $WERCKER_SOURCE_DIR/personal/gang/config.yml
- script:
name: Create personal releases
code: |
zip -j zips/ignoreme.zip $WERCKER_SOURCE_DIR/personal/ignoreme/*
zip -j zips/gang.zip $WERCKER_SOURCE_DIR/personal/gang/*
cp -R zips $ORG_SOURCE
Building on all the previous work, I added the above to my wercker.yml file. What happens here is that first I create a couple of directories and copy the required files in there. To keep it simple, I just created a directory per Lambda function. After this I then use my new s3get step to retrieve the configuration files and place them in their respective directories. The last step zips these files up and copies them where I can use them.
In the deploy step I then added another section as well, where I use my Lambda deployment step to ensure these files are deployed.
Global environment variables
You may have noticed that I have access to the $AWS_ACCESS_KEY and $AWS_SECRET_KEY variables, despite this being a build step. While I haven’t mentioned it before in any of my articles, Wercker also allows you to set up global variables instead of just deployment variables. The process for this is slightly different.
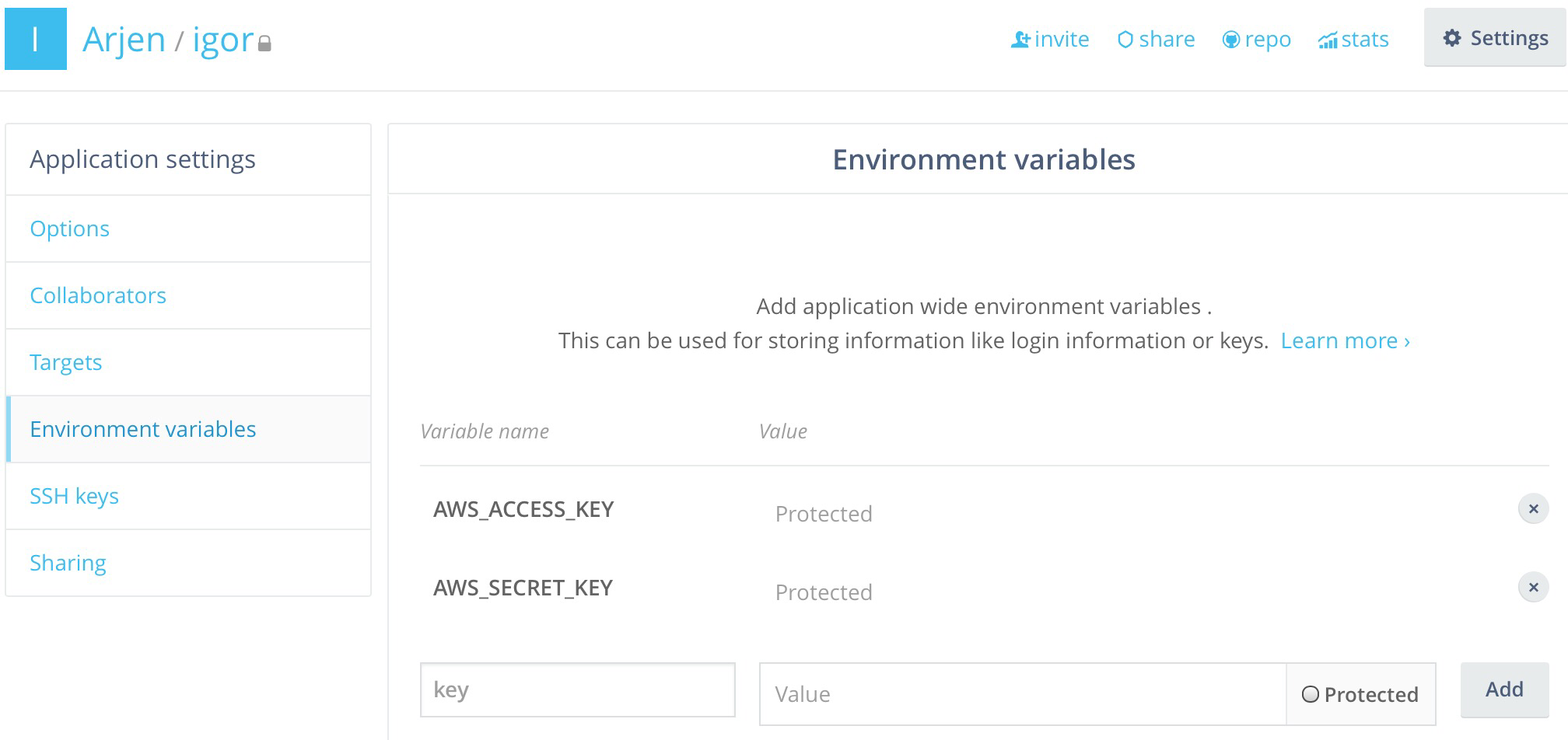
In the settings of your application there is an option called Environment variables where you can set these global variables. Any variable you set here will be available in both build and deploy steps, and in fact I use the above variables with both the s3get and lambda steps.
Upcoming features?
While the step is sufficient for my current needs, I will probably add support for versions to it as that is a good feature to have. When this will happen I don’t know, but it’s unlikely to be very soon. If you feel like adding that (or anything else) yourself feel free to do so and create a pull request. Feature request and bug reports are of course always welcome as well and as always this can all be handled through GitHub.