Managing autoscaling for containers in ECS is a bit complicated, so I decided to write it down so I can refer to it again in the future.
The setup
Let’s assume that we have a container that needs handle messages from an SQS queue. What these messages are, where they come from, and what happens to them is irrelevant. Multiple containers can do this at the same time, and the workload varies over time. Instead of running all containers all the time, we therefore want it to be autoscaling. Usually you’ll want the autoscaling to also include the instances, but for the purpose of simplicity I’m leaving that for another article.
So, we can boil it down to a simple setup: 1 SQS queue, a couple of container instances, and a single Docker image that is deployed on those instances by ECS.

What we want is a CloudWatch alarm to check how many items there are in the queue, and to scale the number of ECS containers based on that. This is both scaling up and down.
I’ll demonstrate this all using CloudFormation1. Below is a description and explanation, but you can find the complete template on GitHub.
Parameters
To make life a little easier, a number of things are provided through Parameters. This includes the container image, SQS queue, and even the ECS cluster. That means this template won’t create any of these services.
Parameters:
parserImage:
Type: String
Description: The Docker image for the parser
ecsCluster:
Type: String
Description: The ECS cluster this needs to be deployed to
sqsQueue:
Type: String
Description: The SQS queue we want to monitor
ECS Task
We will start with the ECS task definition. This will just be a single container, with the image provided as a parameter. I’m also not including anything like mountpoints, open ports, or even logging2.
parserTask:
Type: "AWS::ECS::TaskDefinition"
Properties:
ContainerDefinitions:
-
Name: "Parser task"
Image: !Ref "parserImage"
Cpu: "100"
Memory: "500"
Essential: "true"
ECS Service
We want to run our parser continuously, so we need to set it up as a service. Again, as it’s completely standalone this is pretty straightforward and we can just use the minimal configuration.
parserService:
Type: AWS::ECS::Service
Properties:
Cluster: !Ref "ecsCluster"
DesiredCount: "1"
TaskDefinition: !Ref "parserTask"
Autoscaling Role
In order to do any autoscaling, you will require an autoscaling IAM role. Usually you would probably create a single regional one3 of these that you can use for all your scaling needs, but I added a specific one here.
The important parts here are the service principal, making it usable by the application autoscaling service, the permissions for accessing and modifying application autoscaling and ECS, and access to CloudWatch alarms.
parserAutoScalingRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Statement:
- Effect: Allow
Principal:
Service: [application-autoscaling.amazonaws.com]
Action: ["sts:AssumeRole"]
Path: /
Policies:
- PolicyName: service-autoscaling
PolicyDocument:
Statement:
- Effect: Allow
Action: ["application-autoscaling:*", "cloudwatch:DescribeAlarms", "cloudwatch:PutMetricAlarm",
"ecs:DescribeServices", "ecs:UpdateService"]
Resource: "*"
ScalableTarget
We’ve now reached the trickier parts. In particular I frequently find myself tripping up over the ResourceId definition in the ScalableTarget. The syntax for that is a bit particular, as you can’t just refer to the service you want to run this on.
As ApplicationAutoScaling is built for use with multiple applications, that means it will need a more precise definition. You’d expect in that case that it will use an ARN and parse that itself, but that’s not the case and you need to construct it yourself to reflect (for ECS at least) service/CLUSTERNAME/SERVICENAME.
The rest of this is fairly straightforward. I tell it to use ECS, set a min and max capacity, and have it use the role we created earlier.
parserTarget:
Type: AWS::ApplicationAutoScaling::ScalableTarget
Properties:
MaxCapacity: 10
MinCapacity: 1
ResourceId: !Join ["/", [service, !Ref "ecsCluster", !GetAtt [parserService, Name]]]
RoleARN: !GetAtt [ parserAutoScalingRole, Arn ]
ScalableDimension: ecs:service:DesiredCount
ServiceNamespace: ecs
ScalingPolicy
The scaling policy is where you decide how and when scaling will take place. The documentation on this is a bit hard to comprehend at times, so let me try to clarify it.
The important part is the StepScalingPolicyConfiguration, and then in particular the StepAdjustments. In here you can see 3 values:
- MetricInvervalLowerBound
- MetricIntervalUpperBound
- ScalingAdjustment
You use these 3 values to decide if a scaling action is triggered, and how much it scales. You can have multiple StepAdjustments per policy, but each policy can only scale in a single direction. This is not clear from the documentation and took me time to figure out when I first set one of these up. To scale both up and down you need to define two policies4.
Let’s have a look at how this works. Say we define our CloudWatch alarm to trigger at 1000 items in the queue and we want more instances when the alarm is triggered. The MetricIntervalLowerBound and MetricIntervalUpperBound will be relative to that value. So, if you set MetricIntervalLowerBound to 0, that adjustment will trigger once it hits 1000 items. If you then define the MetricIntervalUpperBound to 100, that means this adjustment will trigger for 1000 to 1100 (1000 + 100) items. If you leave the UpperBound empty, there is no maximum value. Keep in mind that you cannot have a gap between the step adjustments.
This means that you can set it up so that scaling goes faster when you’ve got a big backlog of messages. For example:
StepScalingPolicyConfiguration:
AdjustmentType: ChangeInCapacity
Cooldown: 60
MetricAggregationType: Average
StepAdjustments:
- MetricIntervalLowerBound: 0
MetricIntervalUpperBound: 100
ScalingAdjustment: 2
- MetricIntervalLowerBound: 100
ScalingAdjustment: 4
This will add 2 containers when the queue is between 1000 and 1100, but will add 4 when there are more.
For downscaling, it works similar except that you will need to use negative numbers. So, if you wish to downscale 1 instance when you’re between 900 and 999 instances, and remove 2 when it goes lower you would use the below.
StepScalingPolicyConfiguration:
AdjustmentType: ChangeInCapacity
Cooldown: 60
MetricAggregationType: Average
StepAdjustments:
- MetricIntervalUpperBound: -1
MetricIntervalLowerBound: -100
ScalingAdjustment: -1
- MetricIntervalUpperBound: -100
ScalingAdjustment: -2
Combining these two examples gives you a configuration you can describe in the following image.
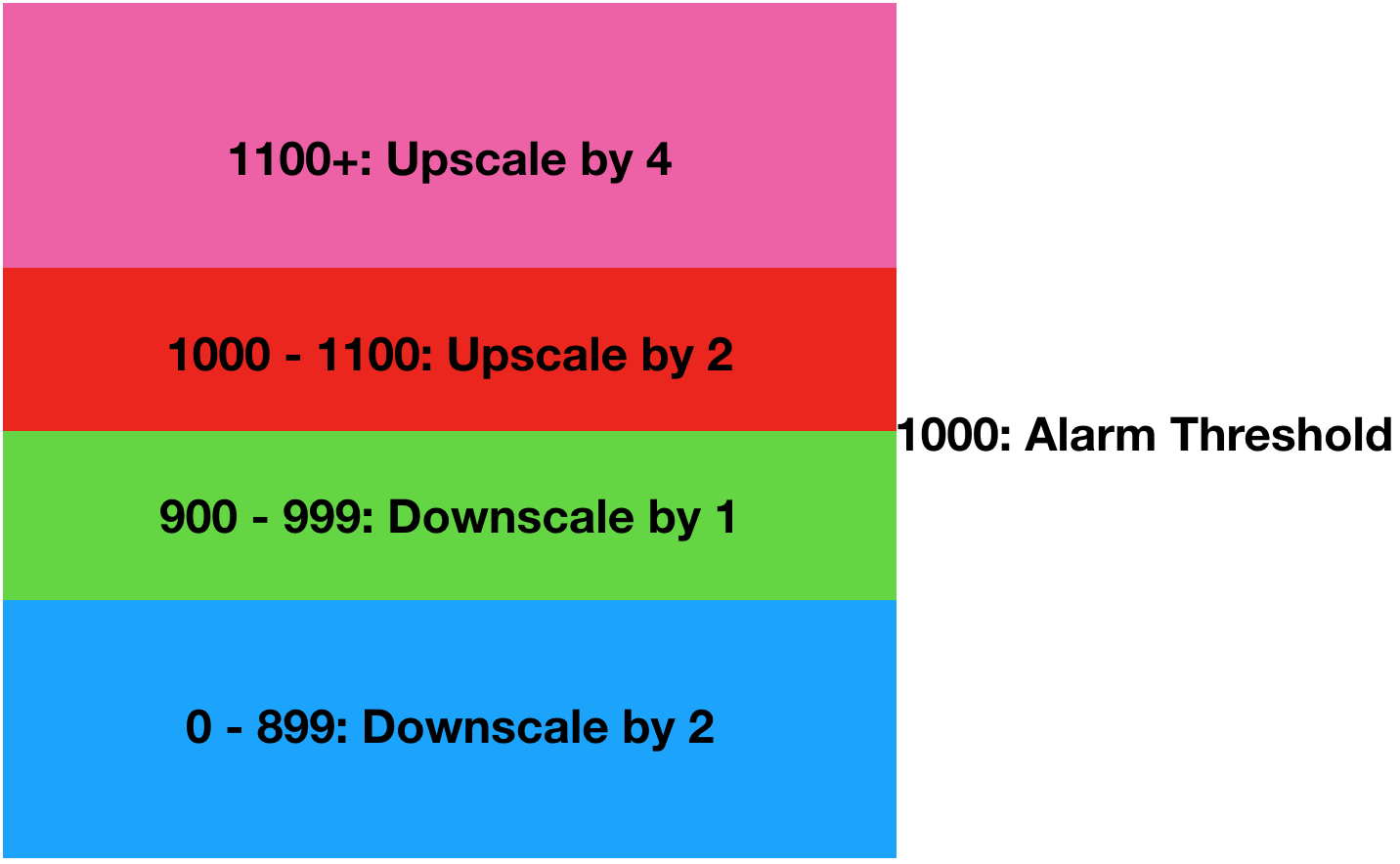
Obviously, this is a slightly extreme example as there is likely an acceptable number of items in the queue where you don’t require any scaling to take place. Using this in the template becomes the below.
ScaleUp:
Type: AWS::ApplicationAutoScaling::ScalingPolicy
Properties:
PolicyName: ParserPolicyUp
PolicyType: StepScaling
ScalingTargetId: !Ref "parserTarget"
StepScalingPolicyConfiguration:
Cooldown: 60
MetricAggregationType: "Average"
AdjustmentType: "ChangeInCapacity"
StepAdjustments:
- MetricIntervalLowerBound: 0
MetricIntervalUpperBound: 100
ScalingAdjustment: 2
- MetricIntervalLowerBound: 100
ScalingAdjustment: 4
ScaleDown:
Type: AWS::ApplicationAutoScaling::ScalingPolicy
Properties:
PolicyName: ParserPolicyDown
PolicyType: StepScaling
ScalingTargetId: !Ref "parserTarget"
StepScalingPolicyConfiguration:
Cooldown: 60
MetricAggregationType: "Average"
AdjustmentType: "ChangeInCapacity"
StepAdjustments:
- MetricIntervalUpperBound: -1
MetricIntervalLowerBound: -100
ScalingAdjustment: -1
- MetricIntervalUpperBound: -100
ScalingAdjustment: -2
CloudWatch Alarm
The last part we need for this is a CloudWatch Alarm to trigger the scaling actions. The interesting part in the alarm below is the Alarm and OK Actions. I’m sending this to both of the policies I set up, but technically speaking you don’t have to do that unless for example you want to start scaling up before the alarm is reached5.
Please keep in mind that the ApproximateNumberOfMessagesVisible metric can be a bit annoying as it takes a while to initially show up and might not always show values if you don’t regularly receive messages in that SQS queue.
parserSQSAlarm:
Type: "AWS::CloudWatch::Alarm"
Properties:
AlarmName: "parserSQSAlarm"
AlarmDescription: "Trigger scaling based on SQS queue"
Namespace: "AWS/SQS"
MetricName: "ApproximateNumberOfMessagesVisible"
ComparisonOperator: "GreaterThanThreshold"
Dimensions:
- Name: QueueName
Value: !Ref "sqsQueue"
EvaluationPeriods: 2
Period: 300
Statistic: 'Average'
Threshold: 1000
AlarmActions:
- !Ref "ScaleUp"
- !Ref "ScaleDown"
OKActions:
- !Ref "ScaleUp"
- !Ref "ScaleDown"
In conclusion,
I hope this was helpful for you. Mostly it’s a matter of just doing this a couple of times to get through the correct syntax and settings, but I still trip over the correct syntax and calculations once in a while.
-
Using the YAML syntax for readability. ↩︎
-
I highly recommend you do configure your logging when actually using ECS. ↩︎
-
Or at least one per cluster ↩︎
-
If I’m wrong about this, please correct me. ↩︎
-
Which can obviously be a good tactic to employ in combination with getting an actual alert if the alarm is reached. ↩︎
Read more like this:
- ig.nore.me For 5 Minutes: AWS Fargate
- Week 32, 2019 - ECS Multiple Target Groups; CloudWatch Logs Insights; PartiQL; CloudFormation Roadmap
- Week 34, 2018 - CloudFormation Secure String Parameters; ECS Docker Volumes; Twitter Breakage
- Week 32, 2018 - Istio 1.0; AWS CDK
- Week 7, 2018 - ECS Target Tracking; User Account Best Practices; APN Cloud Warrior
Or always get the latest by subscribing through RSS, Twitter, or email!